I find entropy to be extremely fascinating. But, matching the formula to its “intuitive” explanations related to prefix free codes and information content is elusive, at least for me. Here, I want to go over a few ways to independently arrive at the idea.
Properties of Information
Suppose we want to define a function , which represents the information content of an event. Abstracting away the specifics of the event, one measure we could use to compare one event to another is their probabilities of occuring. So, could be a mapping from a probability to . Given this framing, the following requirements are sensible:
-
. If an event definitely occurs, it’s not very interesting and gives us little information.
-
should be monotonically decreasing on . A more common event is less informative.
-
Two independent events with probabilities and should have information
The last requirement is the most telling. The probability of two independent events occuring is . So
which only holds for
If we want to be monotonically decreasing,
must be negative. Since , . Letting
Since , we can think of as encoding the base of the logarithm. For convenience, we let be 1.
Entropy is simply the expected value of , over a distribution
We also assume that , motivated by continuity.
Prefix-free codes
Suppose we have a set of symbols that we want to transmit over a binary channel. We construct the channel such that we can send either a or a at a time. We want to find an optimal encoding scheme for , with one requirement: it is prefix-free.
Let’s define an encoding function , which maps symbols to binary strings of length . We say an encoding is prefix-free if no codeword is a prefix of another. For example, is not prefix free because is a prefix of . However, is.
A prefix free code implies that the code is uniquely decodable without additional delimiters in between symbols, which is a desirable property.
Also note that a binary prefix code is uniquely defined by a binary tree:
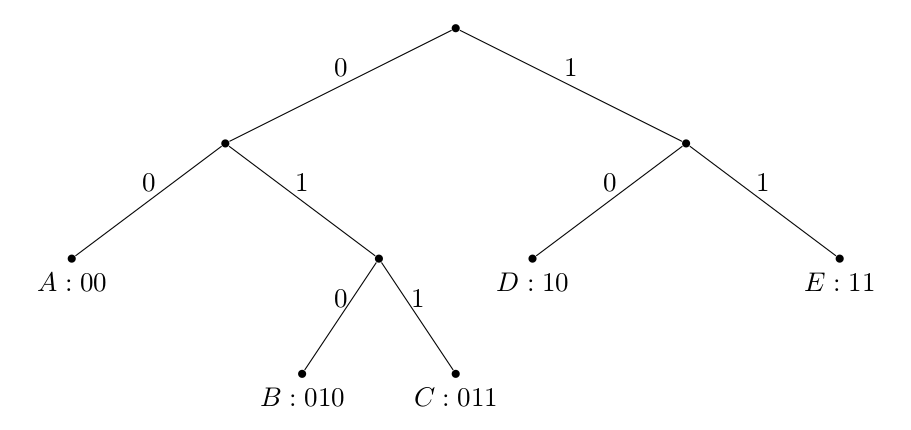
where the root-to-symbol path determines the codeword, and symbols are always leaves. Convince yourself that any construction like this results in a prefix code.
We will now show that the expected codeword length of any prefix code over is bounded by
Kraft’s Inequality

Suppose that is the length of the th codeword. If the code is prefix-free:
Proof:
Let be the length of the longest codeword. We notice that:
- There is at most nodes at level
- For any codeword of length , there are descendents at level .
- The sets of descendents of each codeword are disjoint (since one codeword is never a descendent of another)
These imply
Why instead of equality? Because it is possible that a node at level is not a descendent of any codeword (consider the tree of the code )!
Lower bound for L
Now, let’s consider the expected codeword length
We will show that entropy is a lower bound for , or
Proof:
Where the final inequality is due to 1) KL divergence being non-negative and 2) to due to Kraft’s inequality. One thing to note is that if , . The reason we cannot always achieve this is because may not be an integer.
An Upper Bound for L
Notice that it is possible to construct a prefix code with lengths
since they satisfy Kraft’s Inequality:
By the definition of the ceiling function
Taking the expectation over , we get
This shows that is an upper bound for L!
In summary, entropy is a lower bound, and a reasonable estimate, for the average number of bits it takes to encode a distribution as a prefix code.